Requirements
Env variables
Initialize logger
Initialize MaximOpenAIClient
Make LLM calls using MaximOpenAIClient
Maxim-specific Headers
The OpenAI instrumentation supports additional headers via theextra_headers parameter to enhance trace metadata and organization. You can use the following headers:
x-maxim-trace-id: Associate LLM calls with a specific trace ID (UUID string). All calls with the same trace ID will be grouped together in a single trace.x-maxim-trace-tags: Add custom tags to traces as a JSON string containing key-value pairs. Useful for filtering and organizing traces.x-maxim-generation-name: Assign a custom name to a specific generation/LLM call within a trace (string).x-maxim-session-id: Associate traces with a specific session ID (string).
Example: Using Extra Headers
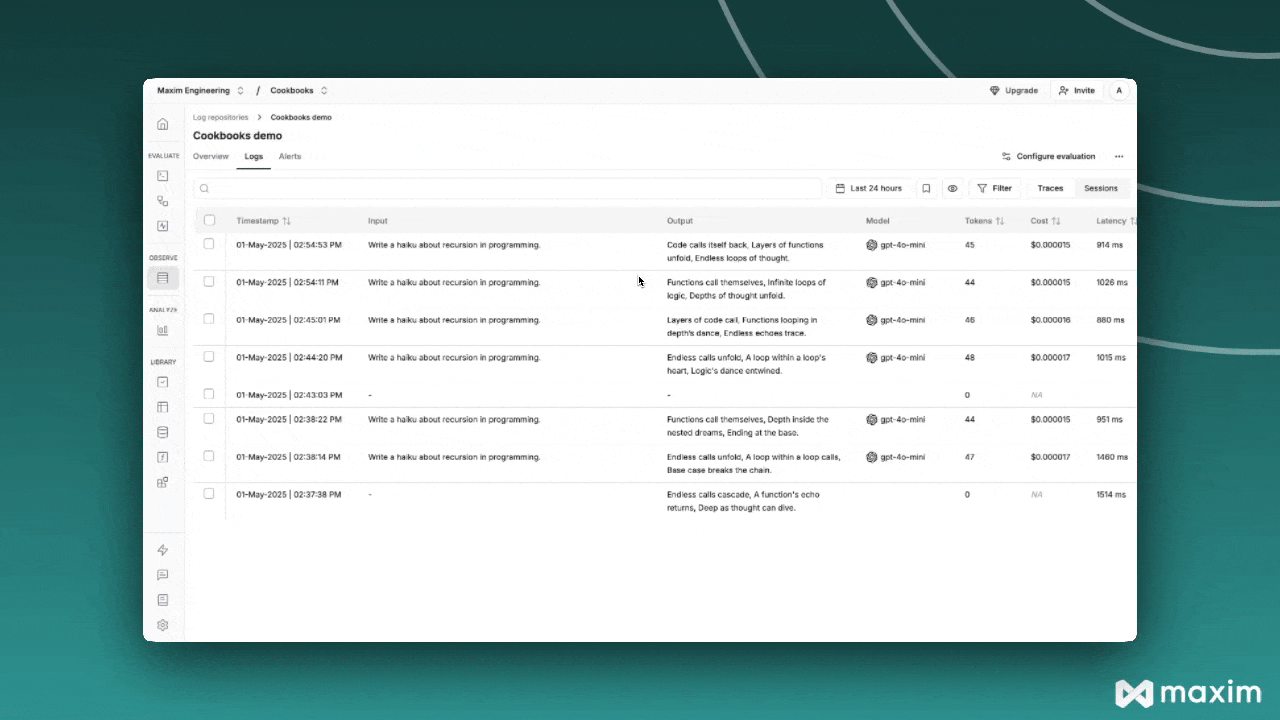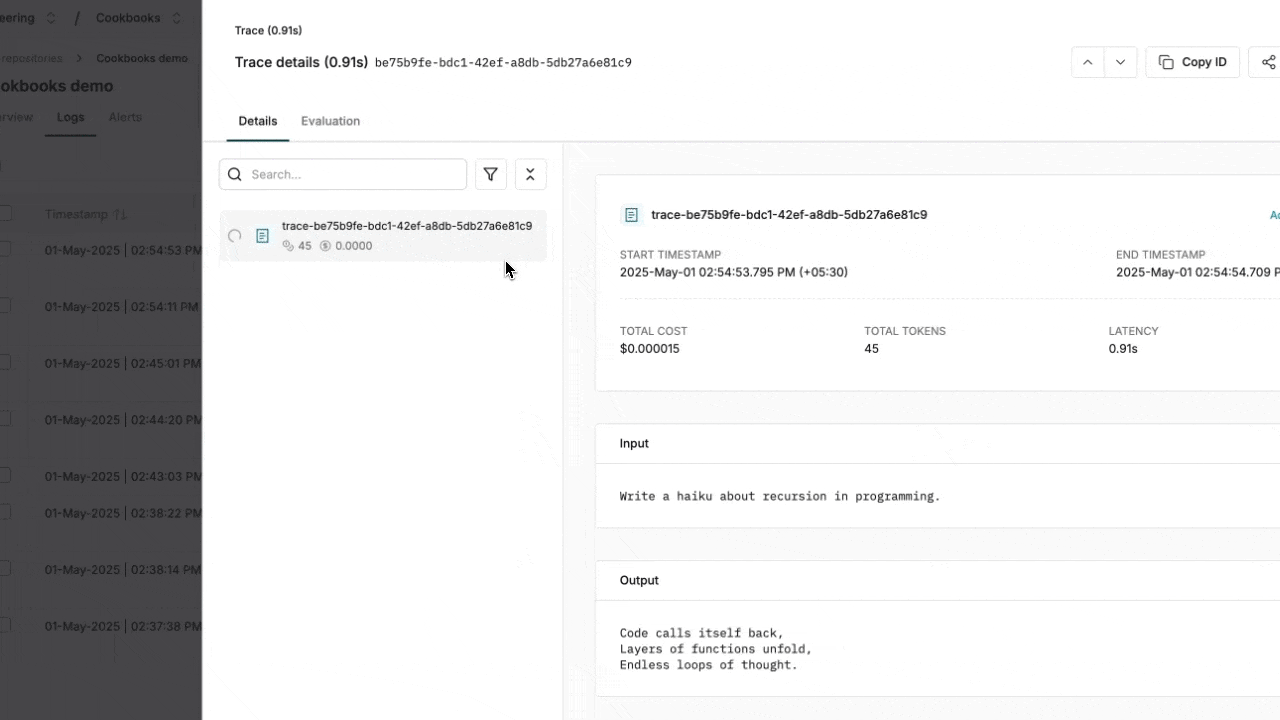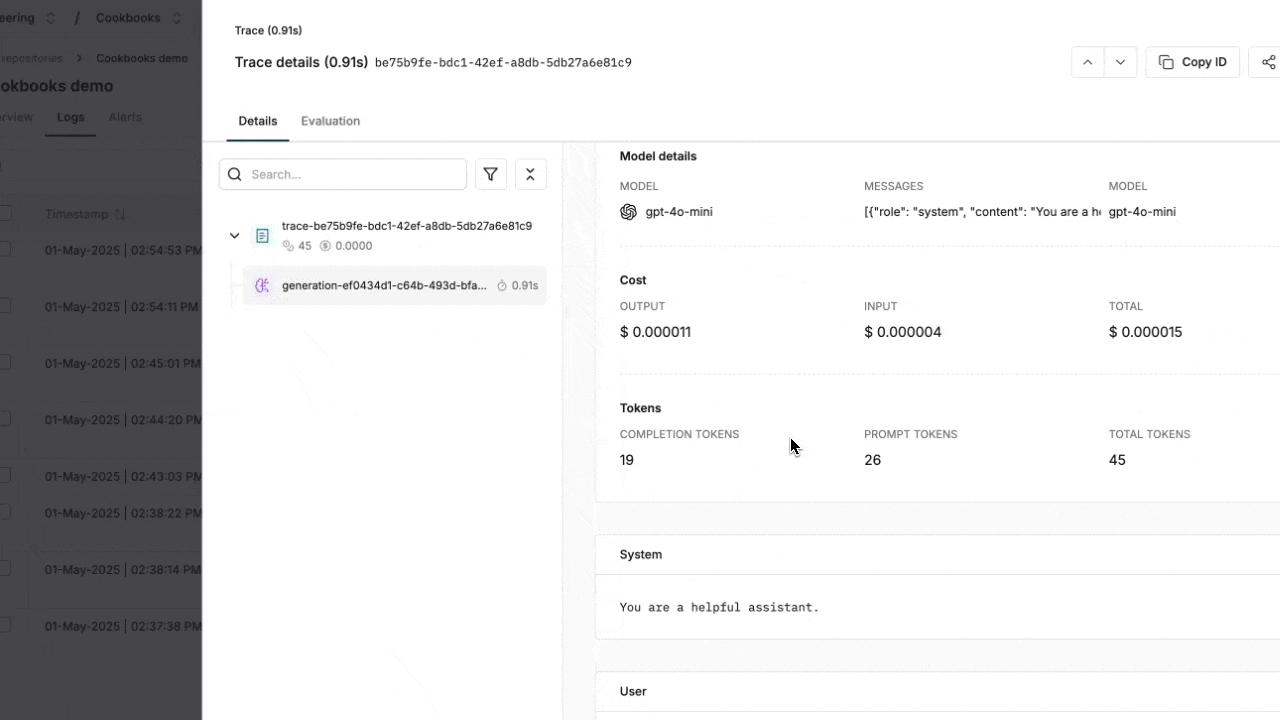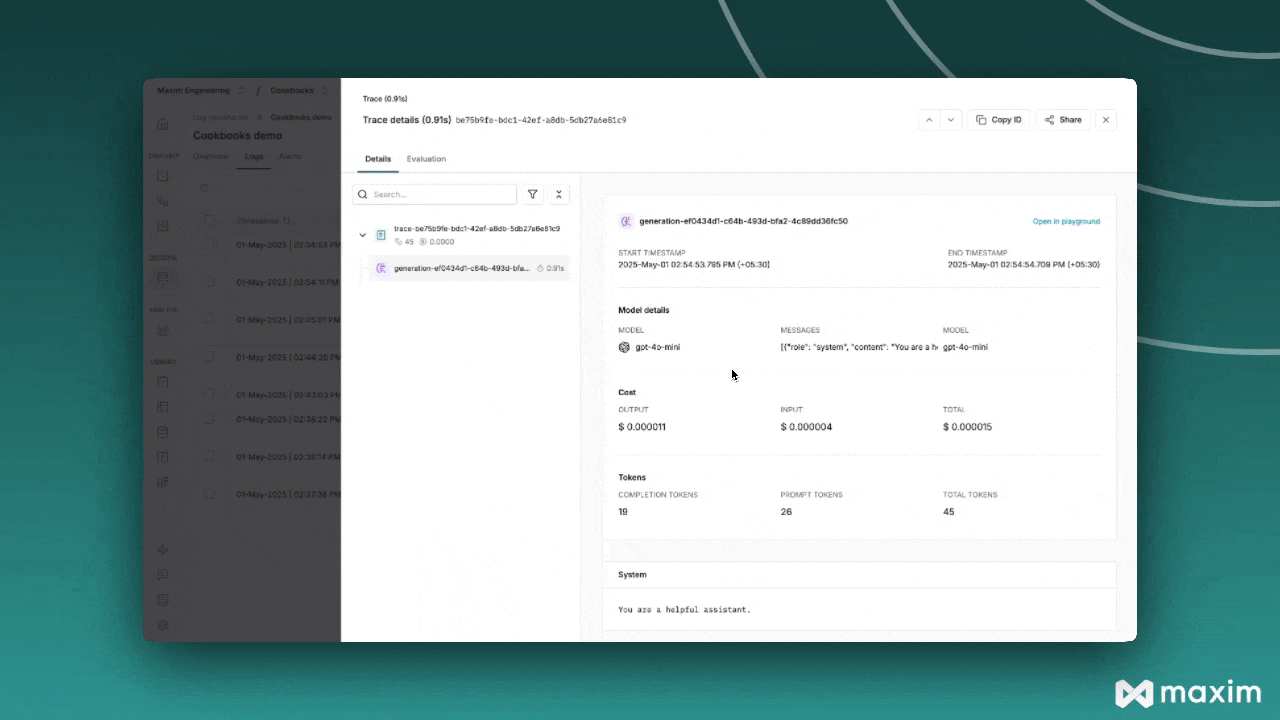
Using OpenAI Responses API
The OpenAI Responses API is the new standard that will replace the Chat Completions API. Maxim provides plug-and-play observability for the Responses API, working with both sync and streaming calls while capturing model, parameters, messages, output text, tool calls, and errors without changing your OpenAI usage.Basic Responses API Usage (Sync)
Streaming Responses API
Async Responses API (Non-streaming)
Async Responses API (Streaming)
Controlling Trace Metadata with Headers
You can pass optional headers viaextra_headers to control trace metadata:
x-maxim-trace-id: Associate LLM calls with a specific trace ID (UUID string). All calls with the same trace ID will be grouped together in a single trace.x-maxim-trace-tags: Add custom tags to traces as a JSON string containing key-value pairs. Useful for filtering and organizing traces.x-maxim-generation-name: Assign a custom name to a specific generation/LLM call within a trace (string).x-maxim-session-id: Associate traces with a specific session ID (string).
Responses API with Tool Calls
The Responses API handles tool calls differently from Chat Completions. Here’s how to use tools with manual tracing:Key Differences: Responses API vs Chat Completions
| Feature | Chat Completions API | Responses API |
|---|---|---|
| Input Parameter | messages (list of message dicts) | input (string or structured input) |
| Response Field | response.choices[0].message.content | response.output_text |
| Tool Calls | response.choices[0].message.tool_calls | response.output (items with type="function_call") |
| Tool Results | Added to messages array | function_call_output with previous_response_id |
| Conversation | All messages in single call | Chained with previous_response_id |
The Responses API is OpenAI’s future standard and supports advanced features like web search. As the Chat Completions API is being phased out, we recommend migrating to the Responses API for new projects.